We are using gstreamer with an appsrc -> nvcudah264enc -> filesink pipeline (simplified). In our application we have also cuda calls and we want to synchronize our calls with the calls of the encoder.
However, it seems it is a hard fact, that the nvcudah264enc creates its own cuda stream and it is not possible to obtain nor set that stream somehow.
According to the Gstreamer release notes 1.24 part CUDA stream integration an automated synchronization is done, if the memory is paired with a different cuda stream than the encoder’s cuda stream. Moreover, this synchronization (gstcudamemory.cpp:703) is done via CuStreamSynchronize (gst_cuda_stream_get_handle (priv->stream)); and that means it is a CPU block.
Our intention would be a GPU only synchronization which would be possible via cuda events, like:
cudaEvent_t event_ptr;
cudaEventCreate(&event_ptr);
// stream 1 records the event
cudaEventRecord(event_ptr, memory_stream);
// stream 2 syncs on event
cudaStreamWaitEvent(encoder_stream, event_ptr, 0);
So long story short: Does somebody know a way, that we can synchronize these cuda streams without CPU block or using only one cuda stream at all, with the current gstreamer interface?
In 1.24, external cuda stream / event is not supported.
But if you can use GStreamer created cuda context and stream, it’s doable.
Option1: Use nvautogpu{h264,h265}enc, instead of nvcudah264enc. The autogpu encoder will configure encoding session by using the first buffer’s associated device context (e.g., memory type, d3d11 device or cuda context, and cuda stream). So in case that you can execute external CUDA operation by using GstCudaContext and GstCudaStream, CPU waiting is avoidable.
To allocate GstCudaMemory with a shared GstCudaStream, GstCudaBufferPool with gst_buffer_pool_config_set_cuda_stream (config, stream) is an option.
Or you can wrap your own CUDA device memory (must be allocated by using cuMemAllocPitch) and wrap it via gst_cuda_allocator_alloc_wrapped()
Option2. Use nvcuda{h264,h265}enc’s proposed buffer pool. Proposed cuda buffer pool will have it’s own stream and you can access it via gst_buffer_pool_config_get_cuda_stream()
Thank you very much, for your fast reply.
I’ve tried to go with the first option. So I am using a GstCudaBufferPool for my input, with a dedicated GstCudaContext and GstCudaStream configured. But anyhow the nvautogpuh264enc seems still be using it own stream.
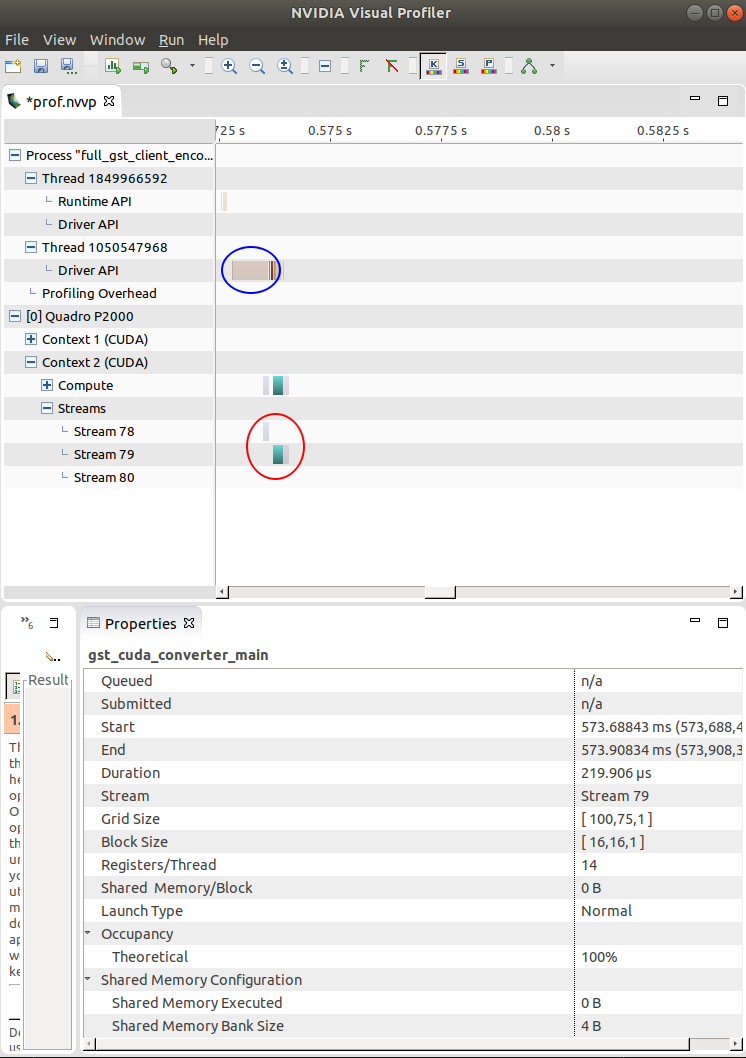
To be more precise about our pipeline, we are using appsrc → cudaconvert → nvautogpuh264enc with following profiling result. Converter & encoder are nicely working on stream 79, but our application calls are on stream 78.
Any ideas about that? Could the cudaconvert somehow here intervene with the stream?
Yes, cudaconvert will allocate output buffer with its own stream in that case.
Current design around cuda stream sharing is, downstream propose → upstream accept (or create new one if downstream does not provide it, to avoid default cuda stream) → forward downstream proposed cuda stream to further upstream.
So, if there are intermediate cuda elements between appsrc and encoder, you need to use nvcudah264enc and cudaconvert proposed pool.
Required steps would be:
- add pad probe to appsrc’s srcpad, and watch caps event, create allocation query using the caps, then send query to convert.
- or do that anytime before pushing buffer to appsrc in paused state, without pad probe
- Extract buffer pool from allocation query (
gst_query_parse_nth_allocation_pool) and gets cuda stream from config (gst_buffer_pool_config_get_cuda_stream)
well, it looks quite inconvenient. feel like we need to implement another interface for this use case
Thank you for that insight.
This could be the way, but yes, it seems quite inconvenient. I think for now, we can live with the CPU block, but we are looking forward to an easier way of accessing this!
Thank you very much!