Hello everybody,
I am trying to build a GStreamer Pipeline like the following (GStreamer 1.24)
appsrc->nvh265enc->h265parse->qtmux->filesink
I create the gst_cuda_context object/stream like so:
CUcontext cuda_context{};
auto result = cuDevicePrimaryCtxRetain(&cuda_context, 0);
gst_cuda_context = gst_cuda_context_new_wrapped(cuda_context, 0);
gst_cuda_stream = gst_cuda_stream_new(gst_cuda_context);
I push frames to the appsrc like so:
auto cuda_memory = gst_cuda_allocator_alloc_wrapped(nullptr, gst_cuda_context, gst_cuda_stream, gst_video_info, CUdeviceptr(image_in_device_memory), nullptr, &FreeFunction);
GstBuffer* push_buffer = gst_buffer_new();
gst_buffer_insert_memory(push_buffer, -1, GST_MEMORY_CAST(cuda_memory));
The input to the Appsrc is a CUDA processed image that is saved in device memory with the pointer “image_in_device_memory” (allocated via cudaMalloc). The format is RGBA8888.
In principle this seems to work, I get a playable video on my hard disk.
Now to the problem:
When viewing the process in the NVIDIA Profiler I see the following behaviour
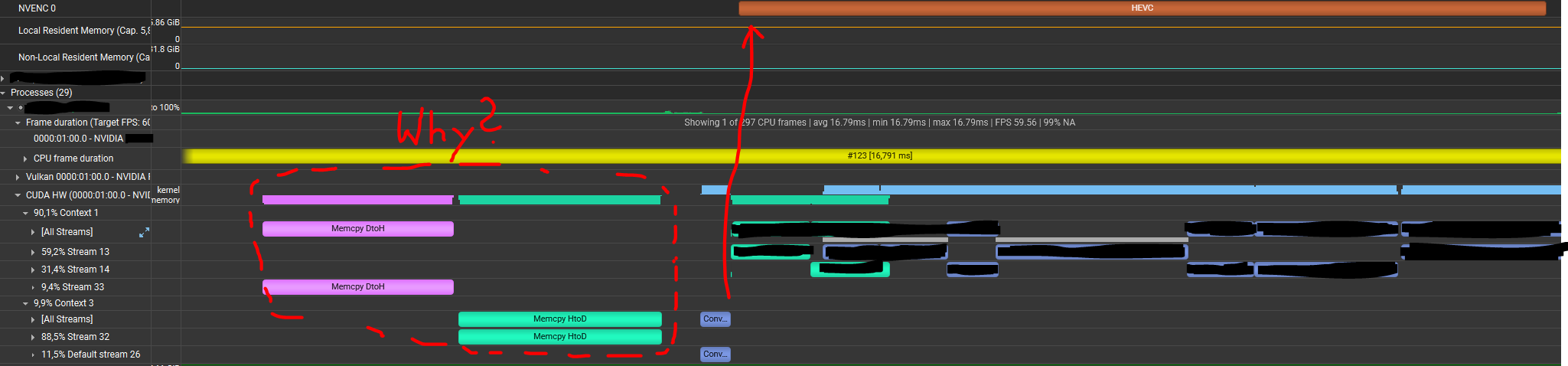
Somehow Gstreamer issues a device-to-host copy followed by a host-to-device copy of the image (even performed by another Cuda Context) and only then the RGB2YUV kernel is running and after that the NVENC/HEVC hardware is activated.
This additional transfer to the host and subsequent reupload confuses me immensely as the data is already on the device to start with.
Can anybody point me in the right direction why this uncecessary process happens? How could I avoid this?
Best regards and thank you